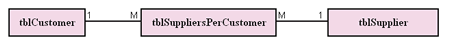Normalisation is the term used to describe how you break a file down into tables to create a database. There are 3 or 4 major steps involved known as 1NF (First Normal Form), 2NF (Second Normal Form), 3NF (Third Normal Form) and BCNF (Boyce-Codd Normal Form). There are others but they are rarely if ever used. A database is said to be Normalised if it is in 3NF (or ideally in BCNF). These steps are descibed as follows: Note: When attribute is used we are speaking of a field in the table 1NF
To put a database in 1N - ensure that all attributes (columns) are atomic (which means that any single field should only have a value for ONE thing).
Examples: In a database a table on Customers would have an address attribute. The address is made up of Company Name, Address Line1, Address Line2, Address Line3, City, Postcode. There are 6 values to this address and as such each should have it's own field (column).
If your company sold furniture a table on products could have a description attribute. If for example that attribute was 'Beech Desk 120w x 75h x 50d'. Ideally this would be broken down into a number attributes like 'Colour', 'Type', 'Width', 'Height' and 'Depth'. The reason for this is it would allow you to seach the database for all Desks, for all pieces of Beech furniture, for all desks with a width of 120 etc. - Create a separate table for each set of related data and Identify each set of related data with a primary key
Example:
In a general Invoicing database you would have a separate table for Customers, Orders, Products, Invoices and you would probably need tables for OrderDetails and InvoiceDetails as well. Each of these tables must have their own primary key. Each of these tables except for customers would have a foreign key reference to the primary key of another table. ( See Relationships below) - Do not use multiple fields in a single table to store similar data
Example:
( Underlined fields are Primary Keys and Italicised fields are Foreign Keys)
In a customer order you could have more than one product. That is the customer has ordered more than one item. If you tried to put all of this in one table as { OrderID, CustomerID, OrderDate, Product1, Product2, Product3} what would happen if the customer ordered more than 3 products. There would also be implications for querying the kind or quantity of products ordered by a customer. Therefore these product fields don't belong in the order table which is why we would have an OrderDetails table which would have a foreign key reference to the Orders table { OrderDetailsID, OrderID, ProductID, Quantity}. Using productID as a foreign key to the product table means you don't have to identify the product attributes here. This also allows you to enter a quantity figure for the product ordered. Relationships:
All tables should have a 1 to 1 or 1 to many relationship. This means for example that 1 customer can have 1 or many orders and 1 order can have 1 or many details. Therefore Orders table would have a foreign key reference to the Customer table primary key { OrderID, CustomerID, OrderDate} and the OrderDetails table would have a foreign key reference to the Order table primary key { OrderDetailsID, OrderID, ProductID, Quantity}. This table also contains a foreign key reference to the Products table. As a product is likely to be ordered more than once there is a many to 1 relationship between the OrderDetails and the Products table. If any tables have a many to many relationship this must be broken out using a JOIN table. For example, Customers can have many Suppliers and Suppliers can supply to many Customers. This is known as a many to many relationship. You would need to create a JOIN table that would have a primary key made up of a foreign key reference to the Customers table and a foreign key reference to the suppliers table. Therefore the SuppliersPerCustomer table would be { SupplierID, CustomerID}. Now the Suppliers table will have a 1 to many relationship with the SuppliersPerCustomer table and the Customers table will also have a 1 to many relationship with the SuppliersPerCustomer table. 2NF
The database must meet all the requirements of the 1NF.
In addition, records should not depend on anything other than a table's primary key (a primary key can be made up of more than one field, only if absolutely necessary like in a JOIN table). Example:
A customers address is needed by the Customers table, but also by the Orders, and Invoices tables. Instead of storing the customer's address as a separate entry in each of these tables, store it in one place, either in the Customers table or in a separate Addresses table. 3NF
The database must meet all the requirements of the 1NF and 2NF.
The third normal form requires that all columns in a relational table are dependent only upon the primary key. A more formal definition is: - A relational table is in third normal form (3NF) if it is already in 2NF and every non-key column is non transitively dependent upon its primary key.
In other words, all nonkey attributes are functionally dependent only upon the primary key. All 3NF really means is that all fields (attributes) should be dependent on the tables primary key. If they are not they should be put in their own table. This means that every attribute unless it is a primary or foreign key must be DIRECTLY dependent on the Primary Key of this table and not on some other column. Example:
The Customer table contains information such as address, city, postcode imagine it also contained a column called shipping cost. The value of shipping cost changes in relation to which city the products are being delivered to, and therefore is not directly dependent on the customer even though the cost might not change per customer, but it is dependent on the city that the customer is in. Therefore we would need to create another separate table to hold the information about cities and shipping costs. BCNF
A relation is in Boyce-Codd Normal Form (BCNF) if every determinant is a candidate key. BCNF is very similar to 3NF but deals with dependencies within the primary keys. BCNF in it's simplist terms just says don't have a primary key made up of more than one field unless it is a join table to disperse a many to many relationship and only contains the two primary keys of the tables it is joining.
Most relations that are in 3NF are also in BCNF. It only happens that a relation which is in 3NF is not in BCNF when the primary key in a table is made up of more than one field and the other columns are not dependent on both fields but only on one or the other. A database is said to be normalised if it is in 3NF and/or BCNF Notes:
Someone asked why normalisation is important. One of our experts Scott Price posted a very useful reply to this in post #15 76  271357 271357 
Thanx
Its a really helpful article.
Thanx
Its a really helpful article.
You're welcome :)
Unequivocal thanks for posting this article, Mary.
i am a learner so it is very helpful.
i am a learner so it is very helpful.
I'm glad to hear it.
If you have any questions post them in the Access forum. We will do what we can to help.
Mary
Unequivocal thanks for posting this article, Mary.
No problem.
You're welcome.
Thank U Very Much For The Article ... It Is Really Helpful For Me ..
Thank U Very Much For The Article ... It Is Really Helpful For Me ..
Thank you.
I'm glad you found it helpful.
Mary
Very nice, it would be good to add something about the rationale of why you would want something normalized. I assume it ease of upkeep and efficiency of searches, etc.
Very nice, it would be good to add something about the rationale of why you would want something normalized. I assume it ease of upkeep and efficiency of searches, etc.
It is!
I'll try to put something together when I get the time. It's a little difficult to explain the reasons why relational database management works in simplified terms but I'll see what I can do. :)
This is very Useful ..Thanks a lot
This is very Useful ..Thanks a lot
You're welcome!
Glad you found it useful.
Great post!
Suggested reading for anyone interested in DB normalisation/design is: Database Design for Mere Mortals Second Edition by Mike Hernandez.
Mike writes in language that the rest of us non-geniuses can actually understand!
Great post!
Suggested reading for anyone interested in DB normalisation/design is: Database Design for Mere Mortals Second Edition by Mike Hernandez.
Mike writes in language that the rest of us non-geniuses can actually understand!
Thanks Scott
Glad you liked it

This reply was given when a member asked why normalisation is important.
My 2 cents worth :-)
Database normalization is a rather arcane topic that you will not be able to really understand until you work your way a little further into the database design process.
Simply put the rules of db design were developed years ago by some mathematicians working in things like 3rd order predicate logic, etc. Access and other db programs are built with these rules in mind. Yes, you can fudge your way around the way these rules/programs are built, but you do so at considerable cost to your brainpower, frustration levels, etc... Some things also not only become much more difficult to do, they can become downright impossible! A much simpler (and far more productive and safe) method is to simply accept that the rules are there for a reason.
As you work on db's more, you will begin to learn WHY the rules are there.
One simple example using your scenario: Suppose you store everything in one big table. Then next year, Quebec decides it doesn't want to be part of Canada anymore (yeah, sure... never happen...). How are you going to change the values in your 'one big table' that refer to Quebec? You will have to write code to search the fields to find each instance of the word Quebec and change it to whatever it gets changed to.
If, instead, you have a normalized db, the change is quite simple: you go to the table named something like tblProvinces, and make one change to the entry Quebec which then affects every entry that it is related to through table relationships. This concept is called data integrity, and is far more important than this simple example illustrates...
Change the example to involve accounting systems and $'s and you will understand perhaps more of the potential errors involved.
For example if you are storing employee salaries in one big table that has all information in it. How are you going to find salaried employees of a certain level of salary? Write code to search the fields to find the instances between a certain $ figure... How are you then going to change each employees salary when they get a raise? How are you going to generate a report to make sure that someone isn't (horrors) making more money than their experience/skill level?
It's only possible to dumb this subject down to a certain point! If you weren't willing to learn how to do it right, you wouldn't be here at this site asking for pointers, so I hope the above information is some help!
Scott.
Thanks dude It was an wonderful tutorial.
Thanks dude It was an wonderful tutorial.
You're welcome. Glad it helped.
Really great article. Congratulations and also thanks a lot for providing us this detailed information
Really great article. Congratulations and also thanks a lot for providing us this detailed information
You're welcome, thank you.
thank you! it really helps
thank you! it really helps
Glad to hear it.
thanks a lot..
Its really helpful.
thanks a lot..
Its really helpful.
I'm happy you found it useful.
Thanks for your excellent tutorial but I would like to ask whether there is a difference in having a compound key (OrderID + LineNo in the OrderDetails table) compared to single field unique key (OrderDetailsID).
Does the DBMS function more efficiently?
Is this a pre-requisite for up-sizing to SQL Server?
I have a stock control system where OrderID is over 125,000 and it is not uncommon to have 10 or more Line items on an order, so my field equivalent to OrderDetailID is very large, and does not do anything for me or the users. All access to the Order Details is either by OrderID, ProductID, Due Date etc.
I have a subordinate table which tracks Batch Number, Quantity Picked so I can calculate profit, print certificates etc., but this is linked (joined) via OrderID + LineNo which is more meaningful (I used to work with dBase and suffered file corruption so often had to recover data. I have only had one instance of this with Access in the last 8 years, but I still like to 'read' the tables!)
I am considering removing OrderDetailsID and SOBatchDetailsID as a step to improve performance (less data should mean less band-width over the network, 'cos Access is sending all data as it is not true Client/Server) Is this a move in the wrong direction because in the longer term I guess will have to upsize to SQL ?
If orders are produced in a batch you can add a foreign key to the order table to allow the batch number to be recorded. However, OrderID should remain a unique single primary key to the table if at all possible.
There are implications in sorting, searching and joining tables when you have a compound key and it should really only ever be used in a join table.
OrderID should be a foreign key in the OrderDetail table and as such you shouldn't need to reference the OrderDetailID at all.
If this doesn't make sense then please let me know.
Sorry if I confused the issue by mentioning 'Batch'. That's another table which holds details of goods received (the stock) from which Sales Order Details (SOD) are picked. As the quantity required on the SOD may require picking from more than one Batch I therefore need a subordinate table (Sales Order Batch Details) to trace which materials have been supplied, and for other functions.
I did not want to bog you down in the details of my application, my question boils down to "If a row MUST be unique by a combination of certain fields (so indexes must exist for them) what additional function does OrderDetailID serve?"
Perhaps I complicated the issue by partly answering my question because I could (probably should!) use OrderDetailID as a foreign key on my SOBD table instead of OrderID + LineNo. However, I prefer to see my data joined by meaningful fields not just numeric 'pointers' and don't know how bad a crime this is! Obviously OrderID is a long integer and not a 15 character alpha-numeric.
Perhaps you might like to write on when 'de-normalization' might be appropriate?
I thought I may have read somewhere that it is necessary to add unique fields befor upsizing to SQL Server.
I realise to you numeric pointers may not seem significant. However, they are very significant to the engine behind your database that processes your queries, searches and sorts.
You say you read somewhere that you have to add them before upgrading to SQL. The truth is it's just as important to have them in Access. It is simply that Access doesn't enforce them.
I realise to you numeric pointers may not seem significant. However, they are very significant to the engine behind your database that processes your queries, searches and sorts.
You say you read somewhere that you have to add them before upgrading to SQL. The truth is it's just as important to have them in Access. It is simply that Access doesn't enforce them.
Your article just made me understand for the first time what a join-table is. I understood before what a many-to-many relationship is, but only in the abstract (so far in my projects I have only had one-to-many relationships). But introducing the join-table concept really crystallizes everything for me.
Thanks!
Pat
Your article just made me understand for the first time what a join-table is. I understood before what a many-to-many relationship is, but only in the abstract (so far in my projects I have only had one-to-many relationships). But introducing the join-table concept really crystallizes everything for me.
Thanks!
Pat
You are welcome Pat.
Hi mmccarthy!
Very glad to You to keep such very good articles in the forum.
Thank You!
Hi mmccarthy!
Very glad to You to keep such very good articles in the forum.
Thank You!
I'm glad you like it.
It Is Really Helpful For Me It Is Really Helpful For Me
I'm happy you found it useful.
Hi ppl. i'm new to here and this article really helped me understand database design in easy words!!i'm also thankful for letting us know abt database design for mere mortals! i am starting a course on principles of distributed database systems. the book i'm referring to is principles of distributed database design by m. tamer ozsu..is there any book that you can recommend which can make it easier to understand like mere mortals?
many thanks for the article, explains a few things that were confusing me!
Have just scanned all the comments very quickly. Someone asked why one normalises. The answer I'd offer is two-fold. First, and most important, it allows the database engine to do its job more quickly. secondly, if you don't normalize, your un-normalized database will come back and bite you when you are asked by a user to do something - usually a summary report - that wasn't originally thought of. Apart from Mary's excellent summary, I think that another excellent explanation is one by Paul Litwin called "Fundamentals of Relational Database Design", which is included in an old Access book published by Sybex.
If there is any interest, I could post a list of other reference sources that I've found useful. This would include the topic of a naming convention, incidentally, for this is an equally important topic, I think.
A concluding thought. Like most designers who use Access, I had to find out the importance of this topic the hard way. I only wish that Mary had written her article when I started (with Access 2 in 1995, I might add!)
If there is any interest, I could post a list of other reference sources that I've found useful. This would include the topic of a naming convention, incidentally, for this is an equally important topic, I think.
You are so right about a database biting you if you haven't normalised. I spend so much of my time fixing these issues. I'm often asked to go in and enhance an existing database with added features and reports. It can be difficult to explain sometimes why current structure of the database won't allow for these features.
Please feel free to post a list of reference sources in a comment here. (No commercial links though). I'm sure many would find it useful.
Regarding the naming conventions, you are right they are an important topic. You can either post them in a comment on here or if you feel like tackling it from an article point of view, feel free to draw up your own article in editors corner on the issue. You can then run the article by any of the Access mods (or myself) and the Chief Editor and get it moved to the HowTo section.
A concluding thought. Like most designers who use Access, I had to find out the importance of this topic the hard way. I only wish that Mary had written her article when I started (with Access 2 in 1995, I might add!)
It's very true. Most people who start using Access without any training in database design are working at a disadvantage. The key to the success of any database (regardless of language) is to design the correct structure first. It may seem a little difficult at first to get your head around the concepts but once you have used them for a while they become second nature.
Mary
Awesome msquared, this article is good and helpful.
If there is a diagram for each NF, then it will be more friendliy.
Awesome msquared, this article is good and helpful.
If there is a diagram for each NF, then it will be more friendliy.
Just arranging something now, will be up shortly.
Just arranging something now, will be up shortly.
Haven't managed to come up with diagrams for 2NF and 3NF yet. Will think about it and come up with something later.
Haven't managed to come up with diagrams for 2NF and 3NF yet. Will think about it and come up with something later.
Thank you for kind and fast response
Good article on the different normal forms, very helpful to all.
One of the additional normal forms, sometimes known as fourth normal form (4NF), is the many-to-many relationship. As stated previously, this is not used very often, however, when you start designing various applications, you may find yourself in need of this.
4NF specifies how to create a many-to-many relationship between tables. Most typically this would be between two tables. The end result here is an additional table comprising of the primary keys of the tables in the many-to-many relationship. Additionally, all fields are part of the primary key.
In other words...
Say you have one table called "users" and another table called "groups." Each table has its own primary key. You want to have a feature which allows each user to join one or more groups.
You would then create a table with two columns: user_id and group_id. The primary key for this table would be both of those columns. This is important for data integrity as you don't want the same user to belong to a specific group more than once.
With this setup, you can easily get a list of all the groups a user belongs to. Just as easily, you could get a list of all the users in a specific group.
Noralization and table structures have always proven difficult for me as well.
JJ
Unfortunately, this is not quite correct.
To give a quick summary, the normal forms are as follows: 1NF: Every row must be an identifiable relation. This means that, in a table, no row may be an exact duplicate of another row, and nor may the row be completely filled with NULL. 2NF All non-key attributes of the table must depend on the entire key. This means that, when a table has a compound key, attributes which depend only on a subset of the key columns should be moved out of the table. For example, take the comment above which mentions a compound primary key of OrderID and LineNo; if the application wants to use invoice_bgcolor to alternate the background color of rows on an invoice, it should go outside of this table, because it depends on LineNo but not on OrderID 3NF You have 3NF pretty much correct above. BCNF Ummm.... what you have up above is actually pretty close to 2NF, but not BCNF. Technically, you could meet the definition of 1NF, 2NF and 3NF by making attribute columns which violate a definition become part of the key -- but BCNF says not to do this. For example, take the OrderID/LineNo example, above. Maybe this company assigns not only an OrderID, but also a ParcelID, which is used internally by the warehouse. OrderID and ParcelID have a one to one relationship, and so both are unique w/r/t LineNo. If we used (OrderID, LineNo) as the key and used ParcelID as an attribute, however, we would violate the 2NF (because ParcelID does not depend on LineNo.) Technically, however, we could make our key (OrderID,LineNo,ParcelID) -- this would still be a unique key, because ParcelID maps 1-1 to OrderID -- but it would violate the BCNF. 4NF The 4NF says that, if you have a compound key, the key must contain only one relation within it. For example, think of a table called student_skills (student,language,sport) This type of table design leads to rows like the following: - Johnny, English, Soccer
- Johnny, English, Baseball
- Johnny, Italian, Soccer
- Johnny, Italian, Baseball
...or even worse, like this: - Johnny, English, Soccer
- Johnny, Italian, Baseball
Now, this is fine if Johnny plays soccer in an English speaking league, and plays baseball in an Italian speaking league, but if that's not the case, this should be broken into two different tables: student_languages(student,language) and student_sports(student,sport) 5NF 5NF takes effect if Johnny does play in leagues with different languages. That's a poor example, but say there were a multi-relation table like student_league_sports(student,league,sport) with these rows: - Johnny,league a, baseball
- Johnny, league a, footbal
- Johnny, league a, soccer
- Johnny, league b, soccer
- Johnny, league c, tennis
- Freddie, league b, soccer
- Freddie, league b, golf
- Freddie, league c, tennis
- Freddie, league c, golf
Now, notice that, since this table already passes 4NF, we don't mean that Johnny plays in league c, and also Johnny plays tennis -- what we're saying is that "Johnny plays baseball, football, soccer and tennis, and he does so in leagues a, b, and c. Freddie plays soccer, tennis and golf, and does so in leagues b and c. In other words, Johnny will play baseball, football, soccer and tennis, but only in leagues in which he is a member. Freddie, likewise, will play soccer, golf, and tennis, only in leagues in which he is a member. Johnny does not play golf just because he is a member of leagues b and c, nor is Freddie a member of league a just because he plays soccer -- there is really a three value relationship here. It should therefore be represented by the following tables: student_sports(student, sport), student_leagues(student,league) and league_sports(league,sport). The data would then look like this: - student_sports
- Johnny,baseball
- Johnny, football
- Johnny, soccer
- Johnny, tennis
- Freddie, soccer
- Freddie, football
- Freddie, tennis
- Freddie, golf
- student_leagues
- Johnny, a
- Johnny, b
- Johnny, c
- Freddie, b
- Freddie, c
- league_sports
- a,baseball
- a, football
- a, soccer
- c, tennis
- b, soccer
- b, golf
- c, golf
Notice that in this case, Freddie would like to play football, but can't.
Finally, as stated above, a table must meet all previous normal forms, ie: 2NF implies 1NF, 5NF implies 4NF, 3NF, BCNF, 2NF, 1NF, etc.
A database is normalized if it is in 5NF. There is also a 6NF and a few more theoretical forms, but they came after the original work in the 70's.
msquared, please don't take this the wrong way -- thanks for putting the effort in to help people understand relational theory, I just want to get the correct info out there, I'm not trying to rain on your parade.
...also, some of the suppositions about why you normalize are also wrong, but this has been a long enough post already :)
msquared, please don't take this the wrong way -- thanks for putting the effort in to help people understand relational theory, I just want to get the correct info out there, I'm not trying to rain on your parade.
...also, some of the suppositions about why you normalize are also wrong, but this has been a long enough post already :)
No offense, taken. Bytes is a democracy where all view points are welcomed and encouraged. I may not agree with all your conclusions but if I've learned anything over the years it's that the more I know the more I find I have to learn.
The only other point I would make is that the premise of this article was to simplify Normal Forms to help people understand Normalisation better. It's a complex subject that is often badly implemented by so called database designers. In a way this was a deliberate attempt to simplify the subject in the hopes of encouraging others to take the structural design of databases seriously.
All comments are always welcome :D
Mary
Unfortunately, this is not quite correct.
...also, some of the suppositions about why you normalize are also wrong, but this has been a long enough post already :)
I was thinking the exact same thing when I read the post. It's great that msquared posted this to help explain normalization, which hardly anyone seems to understand any more, but the forms weren't exactly correct. DirtNap explained it exactly as I learned them many years ago. Thanks for clearing it up.
I was thinking the exact same thing when I read the post. It's great that msquared posted this to help explain normalization, which hardly anyone seems to understand any more, but the forms weren't exactly correct. DirtNap explained it exactly as I learned them many years ago. Thanks for clearing it up.
Its strange, one of the things I remember is that the explanations I got for Normalisation in College a few years ago (Late Student :D) differed in my mind somewhat from how it was taught to me many years ago when I first studied the subject. That may be just my impression though.
Its strange, one of the things I remember is that the explanations I got for Normalisation in College a few years ago (Late Student :D) differed in my mind somewhat from how it was taught to me many years ago when I first studied the subject. That may be just my impression though.
The stuff I posted has been the way it is since the mid 70's, and continues to be that way, although there are some new forms like DKNF and 6NF that are newer, and which I didn't cover (because they are not normally included when talking about "normalizing" a database.) However, if you've learned about this before, say, 1998 and learned about it today, you would get a whole different flavor, because before 1998 you would not have a very large practical component in the training.
Sign in to post your reply or Sign up for a free account.
Similar topics
by: Dinesh Garg |
last post by:
Hi All,
I want to use MS sql server edition 2000. I have installed the server. Now i
want to create the database on this server with tables and triggers. Can
please someone suggest me how to do...
|
by: Arjen |
last post by:
Hello,
If I choose to use a database then I need to use multiple tables. With a XML
file I can select "my objects" as once. I think that there will be around
10.000 records (objects).
I want...
|
by: Shwetabh |
last post by:
Hi,
I am using MS-SQL server to store my database.
My problem is that I have around 150+ database files in DBF format.
Each database file consists of fields ranging from 2 to 33 in number.
Also,...
|
by: kkant |
last post by:
Hi ,
I am KKant from Bangalore, India. I have a jos to do, I have to store VB codes in a a Database (Access) table and in Run time I have to read those codes and Exute them. But I dont know how to...
|
by: DaveP |
last post by:
Hi im looking for a Example of getting
the table structures back to my app.....
TIA
Dave P
|
by: ago |
last post by:
Hi,
Is there any way to compare two identical table structures in access for different values in them.
EG:
Table 1:
Name occupation
rob plumber
Table 2:
Name occupation
|
by: pbmods |
last post by:
Heya.
I'm adding features to a pre-existing project, and I was curious about the way I've been going about designing my database additions.
My methodology is to keep my stuff separate from the...
|
by: Rizki |
last post by:
hai
i want to make the update form for my website, and in my update form there is two combo box for chose where database you want to input the data and where table do you want to fill the field,...
|
by: BarryA |
last post by:
What are the essential steps and strategies outlined in the Data Structures and Algorithms (DSA) roadmap for aspiring data scientists? How can individuals effectively utilize this roadmap to progress...
|
by: nemocccc |
last post by:
hello, everyone, I want to develop a software for my android phone for daily needs, any suggestions?
|
by: Hystou |
last post by:
There are some requirements for setting up RAID:
1. The motherboard and BIOS support RAID configuration.
2. The motherboard has 2 or more available SATA protocol SSD/HDD slots (including MSATA, M.2...
|
by: marktang |
last post by:
ONU (Optical Network Unit) is one of the key components for providing high-speed Internet services. Its primary function is to act as an endpoint device located at the user's premises. However,...
|
by: Hystou |
last post by:
Most computers default to English, but sometimes we require a different language, especially when relocating. Forgot to request a specific language before your computer shipped? No problem! You can...
|
by: Oralloy |
last post by:
Hello folks,
I am unable to find appropriate documentation on the type promotion of bit-fields when using the generalised comparison operator "<=>".
The problem is that using the GNU compilers,...
|
by: jinu1996 |
last post by:
In today's digital age, having a compelling online presence is paramount for businesses aiming to thrive in a competitive landscape. At the heart of this digital strategy lies an intricately woven...
|
by: Hystou |
last post by:
Overview:
Windows 11 and 10 have less user interface control over operating system update behaviour than previous versions of Windows. In Windows 11 and 10, there is no way to turn off the Windows...
|
by: isladogs |
last post by:
The next Access Europe User Group meeting will be on Wednesday 1 May 2024 starting at 18:00 UK time (6PM UTC+1) and finishing by 19:30 (7.30PM).
In this session, we are pleased to welcome a new...
| |