Raymond,
Please keep in mind, many (if not most) companies block 3rd party images and YouTube at the company firewall. As many of us are answering questions during our spare time at work these things are blocked.
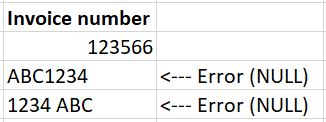
NeoPa(...)It may be that the import is interpreting the first few lines as having numerics in that position and therefore fixes the field as numeric. (...)
I think you have "hit the nail on the head"
Fortunately I'm at home today so I could see Raymond's video. By default the import uses the first 8 or so records IIRC. The first five rows shown in the Excel opening show the values as right-hand alignment which is typical with numeric data and the remaining rows as left-hand which is typical for text/string data; thus, because the first five are numeric, and these are the predominate data type in the records read when the connection is made the parser guesses that the remaining values are numeric.
I have ran into this before with some instrument data and sample names. Some of these start with numeric values and some with alpha values. The data imports correctly if the first value encountered is alpha first for the first 10 or 20 sample names; however, if numeric first for the first 10 or so samples then it pukes (sometimes with just the first sample starting with numeric values!).
I ended up using IISAM and a schema information file to parse the text. Unfortunately, my references for this are at work; however, I did find an article at
Database Journal: Working with external text files in MS Access covering this method - this is quite involved or I would post the steps directly.
PLEASE DO NOT EDIT YOUR REGISTRY as shown in the first part of the article -
SKIP TO THE IISAM portion of the article.
- If you make an error in the registry you can make your OS fail beyond repair and while I will empathize with your pain should that happen... - you have been warned!
One thing to note... I make one schema information file in a "working" directory, use the
FileCopy() to create a copy of the orginal data file in the "working" directory followed by
Name()(click on the links for syntax) to rename the
working copy of the file to a common name used within the schema information file (for ISO I cannot alter the filenames of the original data). Otherwise you have to create a schema information file for each file or build each file into the schema information file - I was importing hundreds of data-files so the standard naming method saved my sanity.