Have gotten to the point where I can't see the forest for the trees as I have the feeling the solution is quite simple!
I have a table with the following columns: job, name of the workmen, days of the week, rate, adj, total and comments.
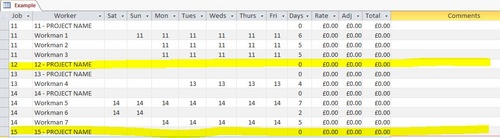
To give an idea of how, a part of, the table looks like, please see below:
Expand|Select|Wrap|Line Numbers
- Job Workman
- 11 11 - PROJECT NAME
- 11 Workman 1
- 11 Workman 2
- 11 Workman 3
- 12 12 - PROJECT NAME
- 13 13 - PROJECT NAME
- 13 Workman 4
- 14 14 - PROJECT NAME
- 14 Workman 5
- 14 Workman 6
- 14 Workman 7
- 15 15 - PROJECT NAME
Expand|Select|Wrap|Line Numbers
- 12 12 - PROJECT NAME
- 15 15 - PROJECT NAME
The code I have at the moment is:
Expand|Select|Wrap|Line Numbers
- SELECT DISTINCT [CISPAYE].Job
- FROM [CISPAYE]
- GROUP BY Job
However, this just returns only ONE column with ALL distinct values (e.g. 11, 12, 13, 14, 15)
I would like to keep the fields when their value appears more than once basically (PLUS the other columns weekdays, rate, adj, etc.). I hope this makes sense!!
If anyone has any suggestions that would be greatly appreciated!
Many thanks,
emperial